Tuesday 21st August, 2018
Machine learning, Style transfer

Monday 13th August, 2018
Yves Saint Laurent

I've been blogging about my admiration for Yves Saint-Laurent's "Homage to Pablo Picasso" dress, and my desire for similar designs on my own clothing. I'm going to write more about this, but I want first to introduce a discipline called "style transfer": using computers to render one picture in the style of another.
A now famous example of style transfer is redrawing photographs to
resemble van Gogh's
The Starry Night. There are loads of illustrations of this on
the web. Here's one, showing a dog photo thus treated:
 [ Image: via "Artistic
Style Transfer" by Firdaouss Doukkali in Towards Data
Science, credited to @DmitryUlyanovML ]
[ Image: via "Artistic
Style Transfer" by Firdaouss Doukkali in Towards Data
Science, credited to @DmitryUlyanovML ]
Here are more, one of which also takes its style from The Starry
Night:
 [ Image: from "Convolutional
neural networks for artistic style transfer" by Harish Narayanan in
his blog ]
[ Image: from "Convolutional
neural networks for artistic style transfer" by Harish Narayanan in
his blog ]
And here are yet more, showing a photo of the
Neckarfront in Tübingen rendered in the styles of The Starry
Night, Turner's The Shipwreck of the Minotaur, and
Munch's The Scream.
 [ Image: via "Artistic
Style Transfer with Deep Neural Networks" by Shafeen Tejani in the
From Bits to Brains blog, from "Image Style Transfer Using
Convolutional Neural Networks" by Leon A. Gatys,
Alexander S. Ecker, Matthias Bethge ]
[ Image: via "Artistic
Style Transfer with Deep Neural Networks" by Shafeen Tejani in the
From Bits to Brains blog, from "Image Style Transfer Using
Convolutional Neural Networks" by Leon A. Gatys,
Alexander S. Ecker, Matthias Bethge ]
Where did these techniques come from, and how do they work? The main principles seem to be these:
1. "Style", as the term is used in this research, means things like the thickness and smoothness of lines, how wiggly they are, the density and distribution of colour, and the surface texture of brush strokes in oil paintings.
2. Style can happen at many scales. I'll demonstrate with the images below. They show a lattice of circles overlaying The Starry Night. The circles are what vision scientists would call "receptive fields": each is sensitive to the visual properties of what's inside it, and summarises these for use in higher-level analyses of the scene.
The first lot of circles are scaled so that they "see" the thickness of
the lines painted round the church. The second lot of circles see the
swirls in the sky: each circle is big enough to see a swirl in its
entirety, so can concentrate on bulk properties such as its width and
curvature. The third lot of circles also see swirls. But I've made them
much smaller, so that they see the strokes making up a swirl, and how
these strokes resemble one another.


 [ Image: incorporates Wikipedia's
The
Starry Night ]
[ Image: incorporates Wikipedia's
The
Starry Night ]
3. Style is spatially distributed. What's important when characterising it is the correlations between different regions.
So what's important about the boundary lines around the church, for example, is that they are all similar. What's important about the swirls is that their constituent strokes are bundled, being roughly the same distance apart, the same width, and the same wiggliness. And in the second image above, we look not at the correlation within a swirl, but at the correlation between swirls, noting how one resembles that next to it.
4. There are programs that, given two images I and J, can calculate how close J's style is to I's. If I were The Starry Night, such a program would be able to work out that the restyled dog photo in my first picture is close to it in style, while the original dog photo is much further.
How do these programs work? They look for spatially distributed regularities, such as those I mentioned in point 3. In principle, a skilled programmer with a knowledge of drawing and painting techniques could write such a program. But it would take a long time, and lots of trial and error, to precisely specify the style used by any particular artist in any particular picture; and then the programmer would have to start all over again for the next picture. So instead, programs have been developed that, given examples of a style, can learn the features that distinguish it from other styles. That's why I've categorised this post as "machine learning" as well as "style transfer".
5. As well as style, pictures have "content". This is the objects they depict: such as the child in Harish Narayanan's examples above. When you change the style of a picture, you want something else to remain unchanged: that's the content.
6. Programs can be written to detect the objects in an image. This was once a vastly impossible task for computer scientists. When you think of all the possible objects in the world — on the Internet, we see mainly cats, but there are also catkins, catalogues, catamarans, catwalks and catteries, not to mention cattle, cathedrals and Catholics — how on earth could one hope to code a description of the features that distinguish them one from another and from non-objects?
As with style, the answer is machine learning — but to a much greater degree.
Before going further into machine learning, I want to mention a project
called
ImageNet: a large visual database
designed for use in research on software recognition of object images.
This was described in
Harish Narayanan's blog post, "Convolutional
neural networks for artistic style transfer". ImageNet contains over
14 million images, divided into groups covering about 21,000 concepts with
around 1,000 images per concept. For example, there are 1,188 pictures of
the African crocodile, Crocodylus niloticus:
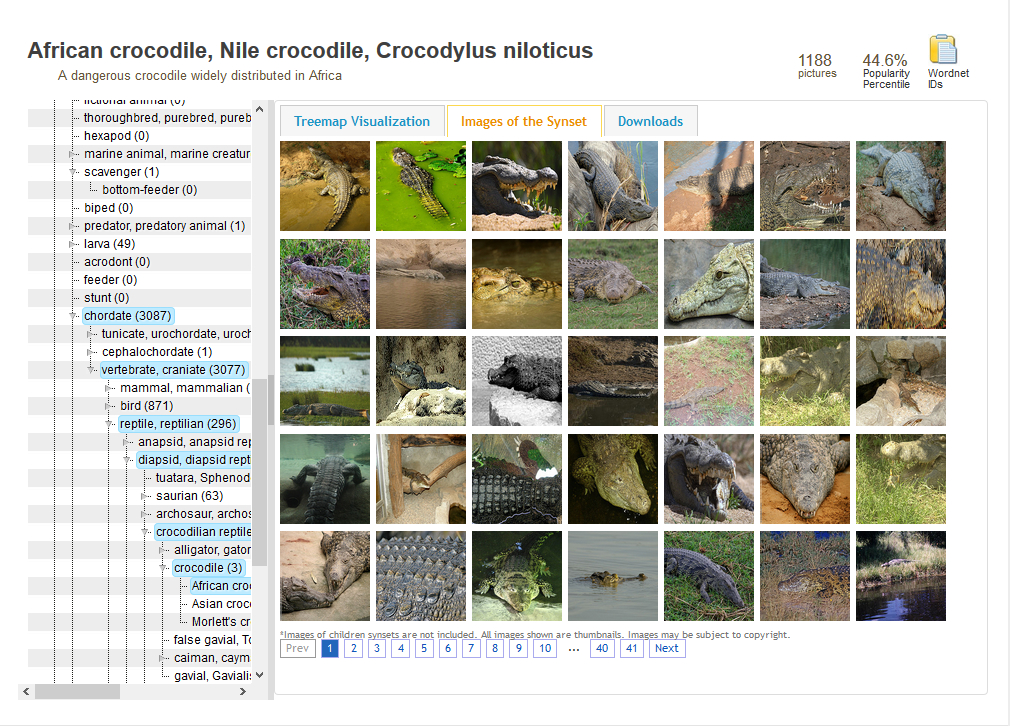 [ Image: screenshot of an ImageNet page ]
[ Image: screenshot of an ImageNet page ]
How does ImageNet know what the pictures are of? Because volunteers have labelled each image with details of what it contains. To ensure that the labelling is consistent, they've followed the conventions of a database of concepts and words called WordNet. This provides a framework within which each volunteer can label in a way consistent with all the other volunteers.
Now back to machine learning. With a database showing crocodiles in all possible orientations, surroundings and lighting conditions, and of all possible colourings and ages; with all the crocodiles consistently labelled; and with all other objects (such as alligators, logs, boats, and newts) also consistently labelled, it's possible to train a suitable machine-learning program to pick out crocodiles and distinguish them from other objects (such as alligators, logs, boats, and newts). The content-extracting programs used in this research have been pre-trained in this way.
7. As it happens, the programs used to learn style are very similar to those used to learn objects. One big difference, I suppose, is the huge pre-training on objects that I mentioned just above.
8.
Another difference is that whereas style information is distributed across
potentially the entire image, object information is "local": that is,
confined to a fixed region. A glimpse of this can be got
from the diagram below:
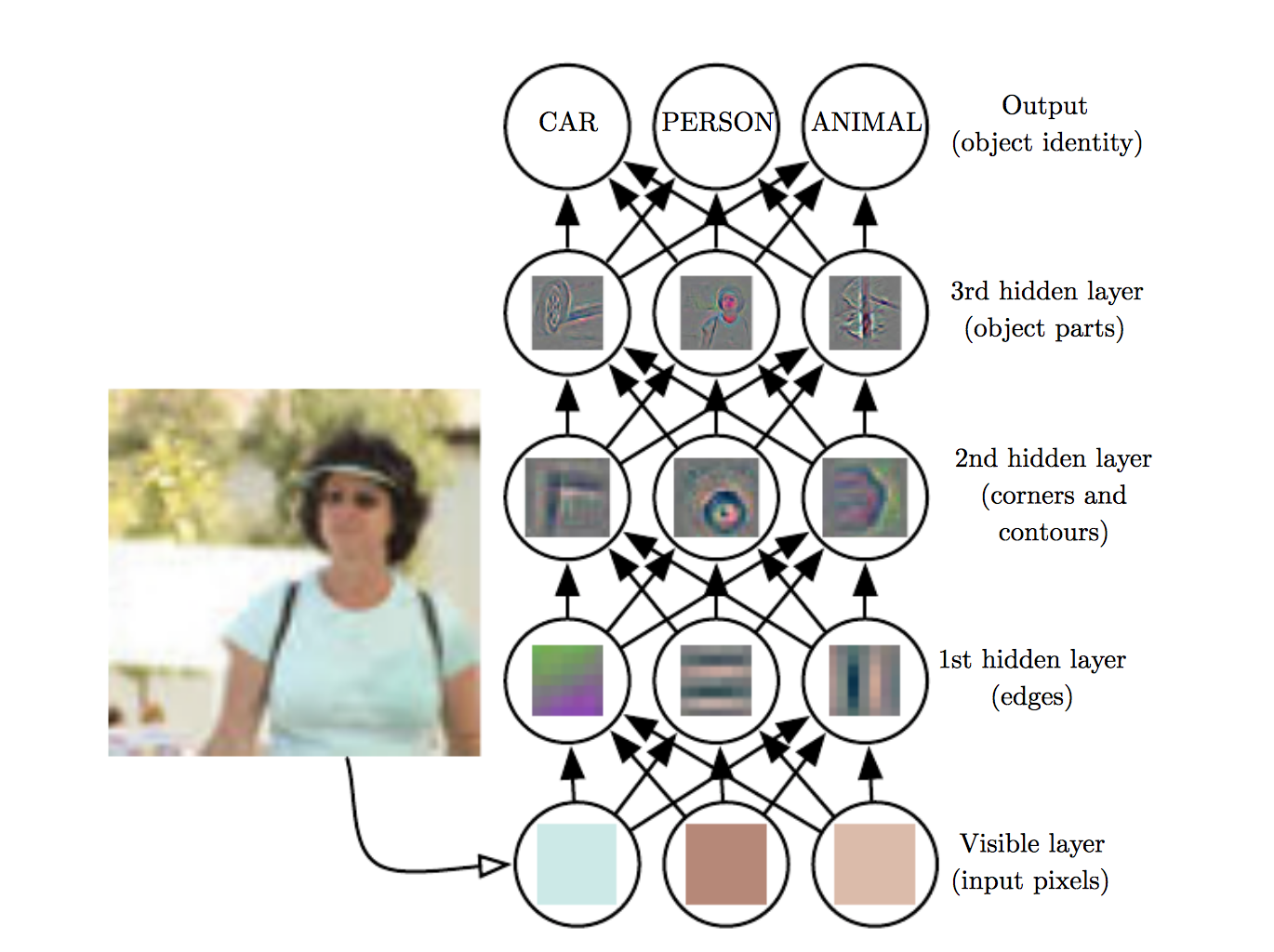 [ Image: via "Convolutional
neural networks for artistic style transfer" by Harish Narayanan in
his blog, from
Deep Learning
by Ian Goodfellow, Yoshua Bengio and Aaron Courville ]
[ Image: via "Convolutional
neural networks for artistic style transfer" by Harish Narayanan in
his blog, from
Deep Learning
by Ian Goodfellow, Yoshua Bengio and Aaron Courville ]
This disgram shows a "convnet" or "convolutional neural net", the learning system used in the style-transfer research I'm covering here. I've taken it from the section titled "How do convnets work (so well)?" in Narayanan's post.
The diagram shows that the learning system contains one layer of receptive fields similar to those I drew over The Starry Night. This layer recognises basic visual features such as edges. It passes its summaries up to a higher layer, which recognises higher-level features, such as corners and contours. And this passes its summaries up to a yet higher layer, which recognises even higher-level features such as simple parts of objects.
As an aside, it's interesting to look at the pictures below of one of my
Moroccan shirts. Would the decoration count as style or content, and what
features might be used in recognising it?

 [ Image: Chromophilia ]
[ Image: Chromophilia ]
9. There's a wonderful demo program recommended by Narayanan, "Basic Convnet for MNIST". This demonstrates how a convnet recognises numerals. Go to the page, and click on "Basic Convnet" in the menu on the left. Then draw a numeral on the white canvas. To erase, click the cross next to "Clear". The second "Activation" layer shows (if I understand correctly), receptive fields which respond to parts of the numerals. You can see from the dark regions, which part of the numeral each field regards as salient.
It's probably worth saying that the features recognised by each layer are not arbitrary, but are (again if I understand correctly), those needed to best distinguish the objects on which the program was trained. So if the objects were the numerals, the upper left vertical in a "5" would probably be important, because it distinguishes it from a "3". Likewise, the crossbar on a "7" written in the European style would be significant, because it's a key feature distinguishing it from a "1".
10. Given two images I and J, we can calculate how close the objects in J are to those in I's. That is, how close J's content is to I's. If I were the original dog photo in my first picture, such a program would be able to work out that the restyled dog photo in my first picture is close to it in content, while The Starry Night is much further. This is the content counterpart of my point 3.
11. So suppose that we have an image I which is The Starry Night, and an image J which is the unretouched dog photo I showed in my introduction. And we generate a third image at random, K. From 3, we can see how close its style is to The Starry Night's, and from 10, how close its content is to "a dog as in my photo".
Now we change K a tiny bit. This will make it either more or less like I in style (The Starry Night), and either more or less than J in content (my dog). And we keep changing it until we achieve an optimum balance of style and content.
But there has to be a tradeoff, because we don't want the style to be too perfect at the expense of the content, and we don't want the content to be too perfect at the expense of the style. (This, of course, is a familiar situation in art. The medium and the tools impose restrictions which have to be worked around. For example, it's difficult to depict clouds and blond hair when working in pen and ink.)
At any rate, this is the final piece in the jigsaw. The style-transfer programs covered here contain an optimiser, which repeatedly tweaks K until it is optimally near I in style (but not at the expense of its content) and optimally near J in content (but not at the expense of its style). The technique used is called "gradient descent", and resembles a walker at the top of a hill taking a few strides along each path down, and estimating which one will get him to the bottom most quickly.
I've included some references below, for computer scientists who want to follow this work up — or for artists who want to persuade a computer-scientist collaborator to do so. The first reference is the paper that ushered in the "modern era" of style transfer, inspiring the methods I've described above. It and the next two references point back at the history of the topic; the third reference, "Supercharging Style Transfer", also describes work on inferring style from more than one artwork — for example, from a collection of Impressionist paintings. The next reference is the one I've referred to throughout this article, by Harish Narayanan; the one after it one is another, briefer but in the same vein. It shows some more nice examples. And the final one is a technical paper on extracting style, referred to by Narayanan: "This is not trivial at all, and I refer you to a paper that attempts to explain the idea."
For more pictures generated by style transfer, just point your favourite search engine's image search at the words "artistic style transfer".
"Image Style Transfer Using Convolutional Neural Networks" by Leon A.
Gatys,
Alexander S. Ecker and Matthias Bethge, Open Access version also published
on IEEE Xplore
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
16 May 2016.
"Neural Style Transfer: A Review" by Yongcheng Jing, Yezhou Yang,
Zunlei Feng, Jingwen Ye,
Yizhou Yu and Mingli Song
https://arxiv.org/pdf/1705.04058.pdf
17 June 2018.
"Supercharging Style Transfer" by Vincent Dumoulin, Jonathon Shlens and
Manjunath Kudlur, Google AI Blog
https://ai.googleblog.com/2016/10/supercharging-style-transfer.html
26 October 2016.
"Convolutional neural networks for artistic style transfer" by Harish
Narayanan in his blog
https://harishnarayanan.org/writing/artistic-style-transfer/
31 March 2017.
"Artistic Style Transfer with Deep Neural Networks" by Shafeen Tejani,
From Bits to Brains blog
https://shafeentejani.github.io/2016-12-27/style-transfer/
27 December 2016.
"Incorporating long-range consistency in CNN-based texture generation"
by
Guillaume Berger and Roland Memisevic
https://arxiv.org/abs/1606.01286
5 November 2016.
{kind=link}